Instrument validation involves two distinct approaches: expert judgment (a qualitative method for content validity that evaluates items based on sufficiency, relevance, coherence, and clarity) and Cronbach's alpha (a quantitative method for internal consistency reliability that measures how well items correlate with each other). The choice between these methods depends on whether the concept being measured is fully defined (requiring only expert judgment), partially defined (requiring both expert judgment and Cronbach's alpha), or undefined (requiring additional exploratory factor analysis). Expert judgment serves as a qualitative tool without statistical coefficients, while Cronbach's alpha is a quantitative tool that belongs to the positivist paradigm, and both can coexist in the same research line as different stages of validation.
Validación de instrumentos: juicio de expertos vs alfa de CronbachAdded:
Good afternoon everyone. My name is José Supo and today we have a new live broadcast.
Before we begin, as is our custom, we're going to ask those of you connected with us tonight to leave a gift here in the comments box, indicating the city you're connecting from, so we can greet you this afternoon as well.
Who's with us here?
Eder Edson Asmat from the city of Trujillo.
Greetings to Net Galaga in Morelia, Michoacán, Mexico.
Luis, a student in Guadalajara, Mexico.
In Huancayo, Edna Mercedes. Greetings to Harry Reyes, Guayaquil, Ecuador.
Good evening to Pedro Enrique, Dr. Porfirio Visoso in Mexico City, Abel Basán in Guaraz, Peru, Elana Codocni, and greetings to Estanislau Pacompía in Puno.
San Cristóbal de las Casas, Chiapas.
Agustín Ruiz, good evening.
Teodoso Gaitán, Lambayeque Mar Duni. Very good. We then have the audio return in today's podcast. [clears throat] Today we have the topic of instrument validation and there are two topics, two very well-known, much-heard phrases, such as expert judgment and Chrombatch alpha.
Why these two topics in the context of instrument validation? Why are they so well known?
Because they are so widely used?
Because they are very famous, so famous that some thesis examiners ask their students, their thesis writers, "Have you already calculated your Chrombatch alpha?"
And the student says, "No, not yet."
Well, I won't check you until you calculate your Chrombatch alpha. Come back when you have your Chrombatch alpha.
There are other thesis committees that ask them, "Have you already done your expert review?" "Not yet," the student tells him. Okay, when you've made your expert judgment, we'll talk, you come back.
as if in every case an expert judgment had to be made, as if in every case a Chrombatch alpha had to be done, but sometimes the ignorance of some makes it so that, to follow a trend, a custom, the thing of a lifetime is that we want to see the Cronbach Alpha or we want an expert judgment to be made.
Well, that's what we're going to talk about today, instrument validation, and we'll certainly talk about expert judgment and also about Chrombatch's alpha.
For this, we need to put ourselves in context.
What is a measuring instrument?
Let's see what exactly a measuring instrument means.
Measuring instruments do not measure; if they do not deliver a final measurement value, they are not instruments. Why make this clarification?
Because many people confuse measuring instruments with [music] verification materials.
A measuring instrument, for example, is a thermometer because it gives the temperature value.
A stethoscope only amplifies the heartbeat, the sound; it does not measure heart rate, it is only for listening and nothing more. A microscope magnifies the image of a cell, of a virus, but it doesn't measure anything. And then many people think that using a stethoscope, a microscope, is using a measuring instrument. That is why in research it is necessary to clearly differentiate the first and last name, measurement instrument, in the sense that all research work needs data and the data comes from measurements, whether they have been carried out by the researcher himself or he has copied the data from records where he did not participate. But generally, what is common is that all research work needs data, and that data comes from measurements, and those measurements are obtained through instruments. Therefore, do not confuse measuring instruments with verification materials. Certainly, I may need an X-ray plate to measure the cardiac silhouette, uh, the cardiothoracic ratio, but the X-ray plate doesn't measure anything by itself. I have to take the measurement with a scale ruler and the radiographic plate becomes a verification material.
verification materials or means of observation in general terms, right?
In terms of measurement they would be observation tools, but in scientific research we know them as verification materials. Verification materials include an X-ray plate, a stethoscope, and a microscope, because it does not measure anything. But we're not going to talk about those today; we're going to talk about measuring instruments. The result of the measurement is a piece of data that can be categorical, that can be numerical, and the instruments must produce precise and accurate results. That's what instrument validation is for: to ensure that the instrument produces precise and accurate results. That's why we're doing this task. And why do we want the measurement results to be precise and accurate? Well, to have repeatable and reproducible measurements.
What do we measure in research?
variables.
Variables are the expression of dimensions or magnitudes.
Dimensions, when we talk about subjective indicators such as academic performance, organizational climate, job satisfaction, are logical dimensions and correspond to subjective variables. But in research we also measure physical magnitudes with objective indicators such as length over time, which when referring to a unit of study, we talk about length as height, mass as weight, time as a person's age, and then variables appear. The nature of the variables depends on the indicators we select.
Remember that for the same variable there can be more than one indicator. Yes. And in some cases, there may be an objective indicator for the same variable and another subjective indicator for the same variable. That can happen. So, it's not that the variables have a nature, but rather that this depends on the nature of the indicator we select. Therefore, objective indicators produce objective variables. Subjective indicators produce subjective variables.
And to measure these objective indicators we need mechanical instruments such as a scale, a height measuring device, and a thermometer. And to measure these logical dimensions of these subjective variables, we need documentary instruments such as questionnaires, scales, or inventories.
Obviously in research, when we talk about measurement instruments and instrument validation, we are referring to documentary instruments. Why?
Because while it is true that when we use mechanical instruments such as a thermometer, a scale or a blood pressure monitor, we buy them already calibrated, and if there is no technical staff dedicated to calibrating them. So that does n't worry us. What worries us are the documentary instruments.
Those are the ones that concern us: the scales, the questionnaires, and the inventories.
Well, to put it simply, a questionnaire delivers a dichotomous result like a pass/ fail exam; these are the results of a knowledge test, and to put it more precisely, a university entrance exam. The results are either you get into university or you don't. That's it. That's a questionnaire, an example of a questionnaire, a typical example. We could force the figure, but I'm talking about a typical example. Then there are the scales that rate the intensity of a response as mild, moderate, and severe. How much does it hurt? Is the pain you're experiencing mild, moderate, or severe?
So, the pain is mild. If tolerable, moderate, we could apply some analgesic; if intolerant, the procedure would have to be stopped.
Or completely agree, indifferent, and completely disagree, like Iker's scale, right? So, here is an ordered result as an ordinal variable. I'm not saying it's an ordinal variable, but rather how it is an ordinal variable.
just to save the concept and in the case of the questionnaire as a dichotomous variable.
Now, the inventories. Inventories include, for example, the multiple intelligences test, which can be non- esthetic, logical-mathematical, or naturalist, and none of the categories are good or bad, as is the case with scales. No category is above the other, they are simply classifications or vocational guidance. After taking a vocational aptitude test, well, some will be drawn to social sciences, others to engineering, and others to health sciences. There is no good or bad, they are simply classifications. Inventories then deliver a final result as a polytomous variable. I'm not saying it's always going to be like this. This is a typical example of a polytomous variable. And so here we have, uh, two scenarios in general terms.
Questionnaires and scales are univectorial.
Why do we say they are univectorial?
Because the questionnaire that gives you pass and fail results are, if we put them on a Cartesian plane, they are on the same line.
Yes, approved, disapproved, right?
So, let's say "disapproved" is lower, and "approved" is higher. You can draw a line. In the case of scales it is also univectoral because mild, moderate, severe, if we put it on a Cartesian plane and you want to draw a line, well you draw a straight line. Or if you want to say strongly disagree, disagree, neutral, agree, and strongly agree, they are on a straight line, just like the questionnaire, only with more levels of graduation. The inventory case is different because if we apply a vocational guidance test, some will show aptitude for engineering, others for social sciences, and others for health sciences. Since neither is good nor bad, there is no one who is above and another who is below. If we put it on a Cartesian plane, there isn't one that's on the left and another on the right, but rather they are in different directions, neither good nor bad, neither up nor down.
So, it's as if they were pointing in different directions, that's why we say it's multivectorial.
What does all this have to do with instrument validation? We do n't find this in books. Nobody has talked about this.
Because? Why do we have to bring up this topic?
This is because instrument validation has to do with this concept of whether they point in a single direction or in multiple directions. In other words, it matters whether it is univectorial or multivectorial for the purposes of validating the instrument that we are going to create and validate.
So, questionnaires and scales will fall into a group called univectorial, and inventories form a separate group, which are multivectorial.
Everything you will find in books, on the internet, in courses, in workshops, everything, everything is related to the creation and validation of univector instruments, that is, questionnaires and scales. That's why when we talk about internal consistency, we think of, for example, Chrombatch's alpha for scales, KR20 for questionnaires, and then there's always the question, what do we apply to inventories? Chrombatch Alpha or KR20 and we don't know, right? Why?
Because questionnaires and scales, being univectorial, share properties.
For example, reliability. Since the inventory is multi-vector, it is validated by dimensions.
Let's assume that an inventory has three dimensions. We have applied a vocational guidance test to a group of students who are about to finish secondary education.
Some develop skills in health sciences, others in social sciences, and others in engineering.
It turns out that this vocational guidance test has at least three dimensions, and we will give a rating for each of these dimensions independently.
The evaluation we are going to do will lead to a final conclusion, but the evaluation we are going to do will be independent. What does this mean?
that each of these dimensions can be an individual questionnaire or can be an individual scale or can be one of each. For this reason, inventory validation is done by dimensions.
Unlike univector instruments, which are questionnaires and scales, we do it in a global way. So, the principles are essentially the same. So that's all we need. Let's get started with our instrument creation.
The development, creation, and validation of an instrument is a line of research. This is why no two instruments are validated in the same way. That's why there's no scheme, no model, no format, no template, just like there isn't in all research, right? In other words, when someone wants to write their thesis or their scientific article, write their paper, there is no strict, rigid template. What we have are principles, postulates, strategies, and methods.
Therefore, the validation of instruments, being also a research design, constitutes and shapes lines of research. If someone wants to build an instrument to evaluate the quality of care in the hospital's emergency service, that would be a line of research, the quality of care, but its design comes down to the validation of instruments.
Yes, if someone wants to create an instrument to prevent workplace accidents in mine workers, then their line of research is workplace accidents in workers, but their design is the validation of instruments.
So, the design is the same, but the lines of research are different, and for that reason the two instruments will be created and validated differently.
We will identify six levels of work for the creation and validation of instruments, from an initial purely qualitative phase to a second moment, a second stage, known as a quantitative phase.
quantitative phase, but we are not talking about the two sides of the same coin. We are talking about the quantitative phase overlapping the qualitative phase, adding to it, climbing on top of the qualitative phase, placing itself above it, using its inputs, absorbing it, and developing it on top of the qualitative phase.
That is the concept of stages or phases or levels of research. What's above doesn't rule out what's below. What's below is an input for what's above. So, there are tools from the qualitative phase, such as the interview.
The interview is a purely qualitative tool, but it is useful for moving on to a second phase, a second stage.
quantitative. So, it's not that quantitative is purely about measurement and statistics, discarding all qualitative tools, no, it's not like that.
The quantitative phase takes advantage of qualitative tools such as phenomenology, hermeneutics, constructivism, and heuristics. All those tools that are clearly qualitative are used in the quantitative phase, only statistical procedures are added, statistical procedures are added, analytics and statistics are added, they are added. So, they are not two sides of the same coin, but two floors of the same building. the qualitative phase and the quantitative phase. This applies to all lines of research and all designs; it is no longer that qualitative and quantitative are divorced, as was discussed in 1950, 75 or 76 years ago, when what we know today was unknown, because it was not known, we did not have that information.
The philosophers with long beards were arguing, smoking cigarettes when they didn't know that it caused lung cancer. These compulsive smokers who sat in universities were arguing about whether this is better if it's qualitative and that is better if it's quantitative.
what were once called paradigms of scientific research, right? The qualitative, the phenomenological, the hermeneutic and the quantitative, the positivism that later transforms into post-positivism, right? Trying to soften the boundary that he had placed on the qualitative ones.
That's a philosophical discussion, that's an epistemological discussion, that's for cigar-smoking, white-bearded philosophers of the 1950s.
All these tools come together and, as tools, not as paradigms, they are used in each phase of the development of a line of research.
So, the first stage, the qualitative one, is purely qualitative, that's true, but the second quantitative stage, in addition to the qualitative tools, includes quantitative tools.
It's an extra, it's a bonus.
Let's talk about the first phase then.
The qualitative phase called content validity corresponds to the creation of the instrument.
And when we are going to work on the creation of an instrument, we are going to create an instrument, because there are three scenarios that we are going to encounter. Let's imagine the battery of our cell phone. In the morning we have it full of green color, stage one. The concept is completely defined, fully defined.
Second scenario, when the concept is partially defined, right? On our cell phone, the battery starts turning orange around midday in the afternoon. Scenario three, when the concept is not defined, our cell phone battery is already in the red, right? It's going to end, we're already worried.
These three scenarios will determine the path for the creation and validation of instruments. In that way?
If the concept is fully defined, then the instrument will be built from the available theory, because there is no discussion about the concepts. Because the definitions are already established, because the theory is consolidated, there is full consensus about the concept that is intended to be measured.
How do we create an instrument? Let's look at scenario one then.
Let's take an example.
We're going to use the traffic rules. Let's suppose we want to create a questionnaire to assess traffic rules in a group of people who are applying for their driver's license.
Create a 20-question quiz with five alternatives each, where only one is correct, about traffic regulations in Peru in the context of an applicant seeking to obtain their driver's license, with the correct answers at the end of the quiz.
In this example, the traffic rules are already published, there is nothing to discuss, that is a consensus, you don't have to drive on the right, for example, you have to stop when the traffic light is red, you have to reduce your speed when you are in a school zone. Nobody disputes any of those regulations; they are agreed upon and consolidated.
So all we need to do is bring up those traffic regulations that are obviously on the website of the Ministry of Transport and Communications, but I'm not even going to look for it because the AI is going to do it for me, right? Even here I have not provided him with the document from which I want him to create a questionnaire. So, here you're going to hand us our questionnaire. We are on stage number one. When the concept is fully defined. Nobody is going to argue with the traffic rules. It is mandatory. They are official, they are agreed upon. We all know what they are. And if someone doesn't know it, it's because they haven't studied them at all, right? So, based on the National Traffic Regulations approved by Supreme Decree number 1629 MTC, the question is, what does the traffic rules exam for obtaining a driver's license primarily evaluate? Alternative A, B, C, D, E, 20 questions.
And here are our correct alternatives. Then it's time to create the interpretation, but for now let's focus on the instrument. So, this is scenario number one, when the concept is fully defined.
Now we are going to do an exercise with scenario number two, when the concept is partially defined. There are issues that are not yet settled.
They are not 100% agreed upon, there is no solid theory regarding it and the intervention of a group of judges is required, but we will still have to create the instrument with the theory that we have available. So, let's do the exercise. In this case, we're going to give the GPT chat a document. What if we give him the research methodology book?
We could give you any document. It is no longer a document, let's say, agreed upon; it is our own document from which we will create an instrument. We're going to tell him to develop a questionnaire.
Well, since the book covers all topics, let's ask him about one particular topic. We'll tell him to create a sample questionnaire, that's it. Or one that is somewhat more debatable. Let's see, about the topics we have here regarding the discussion of results. That's it. Discussion of results.
Everyone knows how to discuss results, but there's no strict manual, is there? So, if we were to create a questionnaire to assess knowledge about the discussion of results, whether for a thesis or a scientific article, we would have to present it to a group of judges, right? So, we're going to tell you the following.
Create a 20-question quiz with five alternatives each, where only one is correct, for the topic of results discussion.
Put the answer keys at the end of the questionnaire, although it wouldn't be necessary to tell him that anymore because he's supposed to have grasped the context from the previous information, right? That's sometimes good and sometimes bad. Well, if the task you're going to do is similar to the previous one, and bad is when you're going to do a new task because it will take the context from the previous one. In that case, we would have to open a new session, but in this case it's a questionnaire, we 've already given you a document.
Then he will look within the book for the topic of the discussion of results and will extract questions to evaluate, let's say, a group of students who are in training. So, we're here to provide context. Okay, here we are, right? Discussion of results.
Let's look at our questionnaire.
What is the main function of the results discussion? Alternative A, B, C, D, E. The 20 questions and then your answer key.
Why does this questionnaire belong to scenario number two and not scenario number one?
Why are there different manuals for preparing the results discussion?
Therefore, in these cases, in this second scenario, it is advisable to resort to a group of judges to proceed with the validation by judges.
That's where the concept of judicial validation comes in, right?
There it is.
So, how is that task carried out?
We're going to follow a route for this. The methodology must have a path, it must have a step-by-step process. Otherwise, it's not a method. It is created in the concept of an idea, which in science is called an epistemological approach, right?
Let's see. It turns out that when we review the literature, and this is step one in creating instruments, reviewing the literature just as when we create a theoretical framework, the concept may be fully defined and in that case we develop the instrument based on the official theory, as we did with the traffic regulations. And the instrument thus created already has content validity through this procedure. Because the instrument was obtained from the official theory, the instrument already has or has rational validity. That's what we did with the first instrument, the instrument of traffic rules. This instrument is endorsed in the National Traffic Regulations approved by supreme decree number 01629 MTC. This one is from Peru. Each country will have one with its own peculiarities, with its own particularities.
So, these traffic rules come from an approved regulation.
Nobody's going to argue with that. Yes, the regulations have been approved, we just need to comply with them and that validates the content of the instrument we have created. For that reason, it is no longer necessary on this first route, on route one, to consult anyone, neither experts, nor judges, nor anyone, right? Simply create the instrument and that's it. Note that we're only talking about content variety; we're not talking about metric properties yet, right?
An instrument created in this way, then, does not require consultation with anyone.
And someone will say, "Is that valid?"
Of course, that's what university professors do all the time.
Do you, as a university professor, think about giving your students an exam the day before or the days prior?
When you sit at your desk with your cup of coffee and start writing the questions you're going to put on the exam for your students, and once you've finished, you administer the instrument, the questionnaire, the exam to see how much they 've learned. Do you consult experts? Are you stalking your colleagues? Let me see if my instrument is well made, it's not well made. No, right? No, it's not necessary. There's no need. Because?
Because the course you teach at the university, the subject you teach, has a consolidated theory.
And while it is true that you have not used the book in the previous days, it is because you are the teacher, and you have already read the book before; it is not necessary for you to read it again now. You are the expert on the subject and what's more, you have read many books. So, it's not necessary. For example, the anatomy professor may come up with the questions from his head, but it's not that he's making them up, it's not what he's read in the books, it's what he's studied and he's going to get the questions for the anatomy exam from there.
That's route one. That is route one of rational validity supported by official theory to achieve content validity. But there is a second route.
Route two is when the concept is partially defined, when there is no definitive official theory, no consensus, and we are left with doubt. So we're going to create the instrument and then present it to a panel of judges. And this is where the concept of validation by judges comes in. It does not appear on route one. And the example I've given is, if you're going to give your students a knowledge test tomorrow, today you sit down, write the questions, and it's not necessary, it's not necessary for a group of judges or anyone to review it.
How do we do that review?
Let's see.
Let's go on route one.
On route one we have a defined theory. Then, we simply proceed to create our instrument. We've done it with Chat GPT, it could be with Gemini, with Cloud, or with your favorite AI.
We need dimensions, we need indicators, and then we need the items and the response forms. That's what we've expressed here in our traffic rules questionnaire. So, we can group it here. Let's tell our traffic rules questionnaire, give it a name and also group it into four dimensions.
We are moving towards the format where we have a concept, we have dimensions that we are now looking for. Why can we do that? Because the traffic rules have already been agreed upon.
Well, the name wasn't strictly chosen. It says, "Questionnaire on traffic regulations for applicants for a driver's license in Peru." Already? So, what we are evaluating is knowledge of traffic regulations for applicants for driver's licenses in Peru. That is its conceptual definition. Now let's talk about dimensions. What are those dimensions? Dimension one, regulatory requirements.
and knowledge test.
Dimension two, traffic lights and light signals.
Dimension three, right of way and safe circulation.
Dimension four, mandatory insurance, infringements and administrative liability.
So, I've identified their dimensions and I'm giving each one an ID so that we can then proceed to write the items, right?
Each item must evaluate one indicator.
In the instrument validation scheme, the dimension is a set of indicators or a set of items. Why do we need to make this distinction? We'll see it when we do the validation by judges. And then there's the form of response. Well, if it's a scale it will be a LER and if it's a questionnaire they will be alternatives.
So, we have now created a content matrix for the creation of an instrument when the concept is fully defined. But on route two we have to do double the work. The first step is to build the instrument, step one, and then step two, to present it to a group of judges for evaluation.
So, in the first case, on route one, we just build the instrument and that's it.
No, because it is supported by the traffic regulations. In route two we built the instrument and then presented it to a group of judges.
We had an example two for this, didn't we?
The example we had given here was about the discussion of results.
Okay, here it is. This was our questionnaire.
Questionnaire prepared on unit 11, discussion of results. Let's tell our questionnaire about discussing results, give it a name, group it into four dimensions, and give me one dimension, one definition for each dimension. That's it, we're building the instrument. I am currently working on the content matrix so that I can draft the instrument.
In this case we're doing it directly, right? Before, it had to be done step by step. Here is dimension one, the methodological sense of the discussion.
Items 1, 2, 3 and 4. Dimension two.
Answer to the purpose of the study.
Item 5 6 7 8 9. Dimension 3, scope and limitations of the study. 10 11 12 13.
Dimension 4.
Comparison and contribution of investigative continuity. 14, 15, 16. is in the rest. So, we have the four dimensions there, with a definition for each of the dimensions, and it has also given it a name, right? Name of the instrument: Knowledge questionnaire on the discussion of results in research.
So, we have already developed our content matrix, we already have our instrument, and in this second route, where we need to go for a set of judges, well, we are going to do that. Once we have this instrument, we will go with a group of judges. So what are we going to do? that they evaluate the sufficiency, relevance, coherence, and clarity of each of the items. Already? So, we create the instrument and then we go to the group of judges.
The suggestions say 3, 5 and 7. Almost everyone agrees on five, but it's not a rule, it's not strict, it doesn't have to be that way always. Sometimes you won't find even three judges, and sometimes you might have 20 judges in front of you; take advantage of them, and you'll already have them in front of you. So you can absolutely do that.
What are these judges going to do? They will evaluate each item in terms of sufficiency. In other words, the items are sufficient to evaluate the dimension and construct that we have written; the answer is yes, not halfway. No, they do fully cover the dimension.
Accepted. They do not meet the size requirements.
delete that item or write a new one.
The items cover the dimension, but require complements. Well, this item needs to be rewritten; something is missing, it needs to be changed. Relevance, does that really correspond to the dimension and construct that we intend to measure?
Because sometimes there are questions that are irrelevant, that have nothing to do with the questionnaire, right? What's he doing there? He's a stranger.
In this case, we would have to remove it if we identify that it is inappropriate, right? If it is relevant, then we accept it. If it's inappropriate, we remove it, and if we have any doubt, we'd better check it.
Coherence.
It evaluates the logical relationship between construct, dimension, and the item, right? There has to be consistency between all of this that we have seen here. I cannot ask a question, an item that I have put in reliability, but corresponds to empathy, to another dimension. I cannot write an item that does not meet the definition of the indicator, which is the operational definition.
The indicator is the operational definition.
Let's remember, ah, I also cannot write an item that has nothing to do with the construct we intend to measure.
Therefore, that item is irrelevant, we remove it.
If it's relevant, we'll leave it as is, and if we have any doubts, we'll check it out.
Sorry, we're talking about consistency. And finally, clarity, right? If the item is clear and understandable, it stays. If it is ambiguous or confusing, incomprehensible, but important, we can rewrite it. If we have any doubts, we should check it.
So, let's go in search of a group of judges. Let's just leave it at five so we don't talk about that topic, which is of little importance at this moment. We're going for five judges and we've prepared an evaluation matrix where we'll place all the items. Uh, if there are 20 items, then 20 rows. We provide all the items with their dimension, their indicator, which is their operational definition, and the wording of the item. So, the judges will rate it as accepted, modified, or non-compliant. It can be with numbers, right? Accepted, two points, modify one, does not comply, zero.
For each item, they will rate sufficiency, relevance, coherence, and clarity.
Well, if it turns out that the item has two points, that's enough, it's accepted. Well, there are no further comments to make, then no. Now, if it has zero points, the observation will most likely be to delete it.
If it scores two points, then there's nothing to note.
If it scores zero points, it will be deleted, and if it scores one point, it will be modified. That's it.
The judge shouldn't even have to write this. This should be filled out by the researcher himself for practical purposes.
This is our decision rule.
So, two points accepted. One point to modify. Zero points does not meet the requirement to remove or rebuild the item. Not necessarily eliminate, it could be rebuild.
And that is what the task of evaluation by judges consists of.
Sufficiency, relevance, coherence, and clarity are the consensus criteria.
Some call it pertinence, they call it relevance. The concept of relevance is broader and more nonspecific. The most appropriate term for validation by judges is relevance.
Well, if someone considers the terms relevance and pertinence to be equivalent, we have no conflict, but the most appropriate term is not relevance, but pertinence. Moreover, there is an absolute concept in all manuals, guides, and protocols to evaluate these four dimensions. However, it is possible to evaluate more dimensions, more criteria, such as validity, whether an item is current or not.
Imagine we were talking about skills in tools for scientific research in university professors.
Well, in the year 2000 one skill for doing scientific research was using AltaVista, wasn't it? In 1995, using a computer would be a skill to strengthen the teacher's research capacity. In the year 2000, Alta Vista would be used.
In 2005, it would be knowing how to search in databases of indexed journals for retrievable information to build a research paper, or it would be using the statistical software SPCS Start Graphic Minit, and in 2026 it would be using artificial intelligence to accelerate research processes, right? For example, to format in APA Vancouver. So, a question that is no longer relevant would not be included.
Objectivity, if what is being asked is truly internally coherent, the strategy, the way of asking, and the structure of the instrument.
Well, this will depend on how much more the creator of the instrument wants to evaluate, but the consensus parameters are sufficiency, relevance, coherence, and clarity. Some people put up to four columns here for the rating, but it's not necessary, three is enough. I simply think the IEMS is fine. If it is our turn to be judges, we say, "The iem seems correct to me."
Okay, there's nothing to discuss. The IEMS does n't seem right to me. My suggestion is that you remove it.
Well, that's the suggestion. And the other would be the midpoint, right? Did you know? The iem is good, but it's not spelled correctly. Already.
And in the observations section we would note that, right? Modify. Uh, and here we write how we should modify that item. At the judge's discretion, because putting four columns here, the first one will always be 100% compliant, the last one will always be non-compliant, 0%. And the two in the middle say, "So-so, so-so." Well, you'd better put it together then, wouldn't you? More or less well, more or less badly, it still requires a review. So why make four columns? Three columns are sufficient. It is sufficient and also has four criteria, it is also by consensus. If anyone wants to add more criteria, welcome, right?
Anything, as Humberto Eco said, the whole thesis is like the pig said, everything is beneficial to him, Humberto Eco said, right? If you want to add more criteria, fine, but you'll complicate things, it will take more time, and you'll confuse the judges. When they see your evaluation matrix so large, they will give up, they won't want to participate, the non-response rate will increase, etc., etc., with all the complications that they require.
Okay, so here are two tasks to do on route number two.
When the concept is partially defined, there are two tasks to do, right?
Build the instrument and when the instrument is already built, go to the judges so they can evaluate it. On route one, there was only one task to do: build the instrument based on the official theory, and that's it, there's nothing more. Don't bother me, that's all. There's no judge here that matters, like a teacher when writing an exam for their students, because the teacher is the expert, since they are the expert in the subject, right? You do not need to consult other professors in the same department. Nobody does that, right? Or someone does that here, right? Nobody does that. Already. Because? Because it has rational validity, because the questions were taken from the book. And he's also read a lot of books, so he has the knowledge and expertise to create such an instrument almost from memory, knowing that this knowledge has sources and could be referenced, right? However, in route number two, the theory is not solid. You have to do the same task as route one, build the instrument, but also additionally go with a group of judges to evaluate them. That's it.
That's route number two. And now comes route number three.
Route number three, but not before looking at some questions. Let's see, says Dr. Porfirio Visoso, "Because inventories are multidimensional, that's why there is an alternative and null hypothesis for each dimension."
The null and alternative hypotheses are used to test propositions.
And when we talk about instrument validation, let's see, here when we talk about validating instruments, those propositions can appear, for example, at the level of stability, right? Whether the instrument is stable or unstable.
But at the level of content validity there is no hypothesis. Therefore, the presence or absence of hypotheses must be evaluated at each stage of the validity of the instrument. It is not a general hypothesis. This instrument is valid in general, no, it is not valid in general, but in each of the parts. We will see that in some cases there are hypotheses, in other cases there are not.
In this first stage of the content assessment, there is obviously no hypothesis because it is purely qualitative. This is qualitative research. Content validity is qualitative research. Everything we have learned and the principles that apply to qualitative research apply here. Exactly.
Luis Fernando Sabogal asks, "Why is Cronbach's Alpha no longer sufficient for reliability if other measures like McDonald's Omega or Chrombatch's Alpha are required?
Because even the latter isn't enough. We'll discuss this topic as well. We'll talk about Alpha and Cronbatch. We'll cover this when we discuss reliability.
Cronbach's Alpha belongs to reliability. Validation by experts belongs to content validity, to two completely different aspects.
Why did I choose these two phrases for the title of this podcast? Because, firstly, some people think that everything is validated by experts. There are people who think that way. Then there's another group that thinks everything is validated with Cronbach's Alpha, and they're at odds with each other.
And why are they at odds? Because of these blessed paradigms of qualitative and quantitative research, because of those long-bearded, pipe-smoking philosophers who died of lung cancer in 1950 because of them, when in reality they are tools for scientific research. Validation by Judges' validation is a purely qualitative tool; there are no coefficients involved, which is why there are three judges, five judges, or an odd number of judges, right?
The author of the instrument decides whether the item stays or goes, taking into account the judges' suggestions—that's why you consulted them. There are no coefficients, no additions or subtractions. So, the number of judges could be 4, 2, 6, 8, or 20.
I like 20, but sometimes it's difficult to find them. 20 judges. So, let's see that judges' validation is a purely qualitative tool, while Chrombatch's alpha is a purely quantitative tool; that is, it belongs to positivism, if you will.
I don't like to use those terms.
Chrombatch's alpha is purely quantitative, and yet Chrombatch's alpha and judges' validation coexist in the same line of research for instrument validation. They coexist.
So, it's not that qualitative and quantitative are divorced.
They're two different worlds. No, they're not. They're part of the same line of research, like any other line of research, even outside of instrument validation.
Dr. Porfirio asks, "Just as in epidemiological, experimental, and ecological designs, in the design of instrument validation, are there one or several objectives for each research level?" There are several. There are several, because if we consider that a line of research isn't exhausted by a single study, a classic line of research, a textbook line of research, is the one we know about diabetes, right?
First, the exploratory level: diagnosis of diabetes.
Descriptive level: prevalence of diabetes.
Relational level: factors associated with diabetes. Explanatory level: causes of diabetes. Predictive level: chronic complications of diabetes.
Applied level: treatment of diabetes. So, as we see, each of those... Each stage of a study has its own objectives. The same is true for instrument validation. Exactly the same. So, content validity has objectives, construct validity has objectives, reliability has objectives, stability has objectives, criterion validity has objectives, and the same applies to performance.
The thing is, in these instrument validation designs, it's possible to complete everything in a single research project. This is possible because the object of study is an instrument.
If we compare a questionnaire to assess knowledge of traffic rules in Peru, it's not the same as a research project on diabetes, right? It's not the same.
Traffic rules as a research project is quite short, quite small, but diabetes as a research project is a whole world. There are specialists who are diabetologists, there are specialized journals dedicated solely to diabetes, there are theories, there are studies about diabetes, there are volumes upon volumes of publications on diabetes.
So, diabetes As a line of research, it requires that programmatic strategy of going step by step, right?
But creating an instrument to evaluate traffic rules—you can cover all six levels, basically, in a single study, yes? But with different objectives for each step, for each level we go through, with different objectives.
And then this will happen: at the level of content validity, we'll use expert validation, and at the level of reliability, we'll use Cronbach's alpha. And someone will say, "Is that a mixed method?"
No, that's not a mixed method.
The mixed method doesn't exist. What exists is the mixed paradigm. The idea that you can mix the qualitative paradigm with the quantitative paradigm. Does anyone believe that can be mixed?
It exists because there's someone who believes that, right? That is, there's the person who believes in that. That's why the paradigm exists, but the mixed method itself doesn't.
Why? Because method means route, method means step by step. Step one, step two, step Three, something that exists in quantitative research, something that exists in qualitative research with each of its designs, but you can make use of both qualitative and quantitative tools, such as expert validation, a qualitative tool, and Chrombatch's alpha, a quantitative tool for the same instrument, but they are two distinct stages in the development of the same line of research. They are two stages, two distinct purposes, two purposes that are ordered. No, they are not achieved at the same time.
Katy says, "Why necessarily opt for expert validation of instruments?" That's a good question, isn't it? So, why necessarily?
I think Katy's question has something hidden behind it, and she's saying, "It seems to me that in some cases it's not necessary, right?" That's what Katy is trying to convey, and what you're thinking is true. It's true. It's not necessary in all cases because it will only be necessary when we're on route number two, right? When the concept is partially defined, as we said, there are non- consensual definitions of the concept, there are proposed instruments for the concept, dimensions can be established with which the concept is measured, and by doing so we construct the instrument, but then we have to submit it for validation by judges. It's not the case that we have official theory, it 's not the case, right? Like when a university professor creates an exam for their students, administers it the next day, and doesn't have to consult anyone. They don't have to consult anyone, and what they 're doing is fine because their instrument has rational validity.
Well, we would say that scenario one, route one, is the easiest of all, right?
Uh, it's a trick. If someone wants to construct an instrument in record time, choose the Route one, so choose the case where there's an official, consolidated, definitive theory, right?
And you're going to build an instrument in record time.
Well, in case there isn't a solid theory, we go with route two. And now let's go with route three, when the concept isn't defined or is weakly defined in this diagram, in this infographic about an analogy with cell phone batteries, right? When the concept is fully defined, it says 100% green. In reality, that doesn't exist, 100% knowledge doesn't exist, because even traffic rules can change [sighs] when the concept is partially defined, 50%, but this is just a reference point, right? This is only a pedagogical strategy, right? It can be more than 50%, less than 50%.
And scenario three, when the concept isn't defined, it's not that it's at zero, because something is known, right? It's at 10%, 5%, but the fact is that it's okay. Down below. And that's route three, when the concept isn't defined, and that's where we run into problems because we're going to have to do several tasks. What tasks are we going to do there?
Well, I think logically, it's clear that we're going to do more tasks than in the first two cases, right? If we make this simple argument, look, we said that in route one, when the concept is fully defined, we only have to build the instrument and that's it.
We're only talking about content validity. Remember, we build the instrument and that's it.
In route two there are two tasks, right?
Building the instrument and then presenting it to a group of judges for peer review. So, logic suggests that in route three there are three tasks, okay?
So, for route one, one task; for route two, three tasks; for route three, three tasks. What are those three tasks?
We're going to have to conduct open-ended interviews with the population. Let's suppose I want to build an instrument to assess TikTok addiction. I used to give this example many years ago and People were laughing, but it turns out there are people addicted to TikTok. It's going to be a diagnostic category soon. Uh, [sighs] it turns out there are people, uh, but there isn't a manual, there isn't a book, it doesn't appear in the DSM-5, the Diagnostic and Statistical Manual of Mental Disorders. It's going to appear in the sixth version, right? Social media addiction. There have been some really complicated cases about this. Well, uh, how do I know what to ask? How do I know how to build this instrument if there isn't an official book that talks about TikTok addiction, social media addiction? Well, there's theory about addictions, but not about social media, right?
Because this is something new, except for the short 15-second videos, right? They're there with their finger on their phones all day. So, what do you think if we go and ask those young people, especially the young people who are on TikTok for 8 hours straight?
To the finger.
What are they doing there? No, they're talking, they're playing, because some of them play online, uh, they're studying, maybe someone's studying too, right?
What are they doing? How many hours do they spend connected to social media?
What are the main activities they do?
Uh? What is their level of accessibility to these platforms?
So, we're not going to ask them exactly what they're doing, but rather what the activity they're doing consists of. It's an open interview.
Types of interviews, right? Types of interviews. Open interview, focused interview, standardized interview. Well, in this case, it's an open interview with the population, the object of study, which will be the recipient of the instrument that we're going to construct, an approach to the population, that's what it's called. And we're going to ask questions to collect narratives, expressions, examples, practices, forms of interpretation linked to the phenomenon. So, we said there were three tasks, right? In route 3 there are three tasks. The first is that. And what are we going to achieve with it?
We're going to obtain preliminary categories, preliminary categories about of the phenomenon we want to address with a view to building an instrument, with dimensions, with items, with all that. We're not discovering anything new; we might discover that there are people who gamble on their cell phones, right? They're placing bets, perhaps.
Once we have these preliminary categories, we're going to list them.
We're going to make a list of preliminary categories, and with this list, we're going to talk to the experts.
If we're talking about social media addiction, TikTok addiction, then I would go and talk to psychiatrists, psychologists, psychotherapists, right? People who are specialists in human behavior, experts in human behavior.
So, I'm going to go with this list; I'm not going to go in with nothing, I have to have something. So, I'm going to go with this list and I'm going to conduct my interview focused on the experts, right?
Remember, there are three types of interviews: open interview, focused interview, and standardized interview. In this case, I'm going to conduct the focused interview with the experts because I already have a list of keywords. We have some predefined categories, and I'm going to consult with these experts to see if this really corresponds to a criterion for addiction.
Addiction has criteria such as, for example, tolerance, right?
And we're going to consult in order to build, to try to build, dimensions and items.
If we can't build dimensions, we'll build the items. Although from a statistical point of view, there's no difference between a dimension and an item.
Dimensionality reduction in statistics refers to a grouping technique such as factor analysis, or as we now call it, clustering. So, in short, what we should develop initially are the items, and only then do we look at the dimensions. We have to develop the items; these preliminary categories will become items, and so on.
So, we're going to do task number two, right? After the focused interviews with the experts, we're going to build our instrument.
So, task number one: approaching the population to conduct open interviews with the target population, and we end up with a list of categories or keywords. Task number two: we take this list to a group of experts with our categories. Preliminary steps, and we're going to finish with a preliminary instrument.
Then, with this preliminary instrument, we're going to apply expert validation. So, the process here is longer, isn't it? First, we have to approach the population, conduct open interviews with the population to extract a list of keywords. With these keywords, we'll conduct focused interviews with experts. From these interviews, we develop the instrument, and once we have the instrument, we go to the experts for expert validation. In this case, there are also three more complicated tasks. So, if someone wants to build an instrument, they're going to take this three-step route. It's going to take them several months of work, several months of work. But instruments created from concepts that aren't yet defined are innovative; they're not original, they're new proposals, new approaches, like if someone were to develop an instrument to evaluate social media addiction and actually identify pathology, right? Cases that degenerate the emotional and mental health of young people, especially, and also of older people. I mean, yes, it would be very It would be very important if someone did that work.
So, we have these strategies for content validity. I want to make a special distinction here between validation by judges and expert interviews.
Let's draw an analogy with a thesis. We already mentioned at the beginning that there's an open interview with the general public. Task one, task two, an interview focused on experts, and task three, validation by judges.
To avoid confusing what a judge is with an expert, because there's a lot of confusion between these two.
The judge is like your thesis committee. Your thesis committee doesn't help you construct the thesis, right? They only evaluate it.
Now, the expert is like your thesis advisor. Your thesis advisor helps you construct the thesis, right?
So, experts help you construct the instrument, but judges evaluate the previously constructed instrument. That's the difference between an expert and a judge. So, the word "judge" is related to function. The function that the judge fulfills is to make a judgment. That's their function. Now, they are also an expert, yes, well, they are also an expert, right?
But their function is to make a Judgment, that's why we call them judges.
Um, the experts who help you build the instrument. We can't call them judges because they're not going to evaluate anything; they're helping you build it.
So, we can call them expert builders. There, to avoid confusion. Expert builders are those who help you build the instrument, and judges are those who evaluate the previously built instrument.
Now you might say, "And can the same person help me in both stages?" Since I have a friend who is also an expert, and I want to invite him to be a judge. Well, you'd be both judge and party, wouldn't you? [clears throat] That doesn't exist, not even in law. You can't be both judge and party because if I helped you build these instruments, how am I going to evaluate them? Because for me, they're fine, right? If I helped you build them, for me, they're fine. The idea is that they should be two different people.
Now, it could be that both are experts, both are endocrinologists.
One helps you build it, the other helps you validate it. Yes, that's fine.
[clears throat] But ideally, there should be two different people for this third stage.
Very well. Let's move on then to the metric properties. We haven't only talked about this qualitative phase. Content validity. We 've already ensured content validity. Now it's time to talk about construct validity, reliability, stability, criterion validity, and performance.
But first, a greeting to everyone present. Let's see, there are a few questions here.
It says, "Validation is a process that is done in a handcrafted way." All [clears throat] scientific research would be artisanal, wouldn't it? Because there is no machine, no automated system to do scientific research. In other words, a study of the prevalence of diabetes in pregnant women is still still artisanal. And it's a good way of saying that scientific research will always be alternative. That's why AI, the misnamed intelligence, let 's call it AI, will never replace the scientific researcher. Because?
Because it's handmade.
Netza says, "Validation is a process that is done in a handcrafted way and reliability is merely statistical, but choosing how we evaluate reliability requires logical reasoning." Ah, there comes the qualitative phase involving statistical tools, and yes, they are inclusive aspects, that is, both are developed in the same instrument.
Very good. We will also invite people who are in Peru. This Saturday, May 16th, we are at our biostatistics headquarters in Jesús María, Lima, with our workshop on scientific research with artificial intelligence. I'll share the link here for those who wish to register. It is a full day where we will develop the entire procedure of a particular design using computer tools.
Obviously, you need to know the concepts. Artificial intelligence is a vehicle, just as we can travel from point A to point B by walking, cycling, driving a car, or flying.
Well, when calculators were invented we were riding bicycles.
When we used statistical software, we traveled by car, and now that artificial intelligence exists, we travel by plane. That 's more or less the analogy, isn't it? The objective of moving from point A to point B, uh, the intention to move is that of the researcher, that of the individual. How does he do it? Based on their resources, cost-benefit analysis is their strategy.
Therefore, artificial intelligence does not modify the principles of science, but rather accelerates the tedious tasks that sometimes have to be done to conduct scientific research. a table of variables with one click, for example, based on a consolidated theory, which you also have to learn to do, right? Lima, Saturday, May 16th at the biostatistics headquarters in Jesús María. There's lima48.com.
Let's now look at the quantitative phase.
Construct validity. De constructo.
There is a concept in the CMIN methodology that is equivalent to construct validity, called structural validity. I was rehearsing it around here, but it 's a much smaller concept.
The concept of construct validity is broader.
Let's keep it as a construct.
Construct validity. Well, in simple terms, that's why some people call it structural validity. In the Cosmin methodology it appears like this, in simple terms it refers to structural validity, to the internal structure, to the factorial structure, that is, to this scheme, right? This is a factorial structure, the factorial structure. So it turns out that if we have an exam, for example, on arithmetic operations for a group of children who are learning mathematics, we are going to ask them questions about addition, subtraction, multiplication and division. And in the case of arithmetic operations, logic tells us that we are going to put five addition questions, five subtraction questions, five multiplication questions, five division questions, that is, the same number of questions, although it will not necessarily be like that in other cases. Not necessarily, but it's a good starting point.
This is the factorial structure, dimensions and items that correspond to each dimension in simple terms.
Construct validity is much broader, but factor analysis focuses on this, which is the best-known procedure.
So we're going to return to our stages once again.
These scenarios are happening again.
These scenarios are important to consider in content validity and now appear in construct validity. Because? Because when the concept is fully defined, as in the example of arithmetic operations, everyone knows that arithmetic operations are addition, subtraction, multiplication, and division. So, the dimensions are already known.
There are other cases, other examples where the dimensions of a concept are not so widely known, but if we read the book we will discover them. For example, human anatomy. When a medical student studies human anatomy, it turns out there is a book chapter on head and neck, there is a chapter on thorax and abdomen, that's two, there is a chapter on upper and lower limbs, that's three, and there is a chapter on pelvis and perineum, that's four.
So, the experts in human anatomy have decided to separate the anatomy book into four chapters. That's it.
Head and neck, thorax, abdomen, lower limbs, upper limbs, pelvis, perineum, that's it. That's how they've arranged the book, and that's how we all study it, and nobody argues. Well, we would also be in scenario one because the dimensions are already known there. So, if I'm going to create an anatomy exam for students, I'm going to respect that factorial structure, right? I will respect that factorial structure. Furthermore, if I don't do it this way, some students might complain and say, "Why?" They gave me eight questions about the head and neck and only three questions about the chest and abdomen. If I've spent all night studying chest and abdomen and haven't gotten to the neck because I didn't have enough time, he's going to complain, right? So, we would have to put the same number of questions for each of the dimensions. So, we're at stage one. There.
The concept is fully defined.
Now, in scenario two, when the concept is partially defined, that is, there is a bit of theory, let's say we are at 50%.
So, we're going to lay out the structure, we're going to lay out this scheme. We are talking about TikTok addiction and we have five questions for the dimension of time spent on the platform, five questions for the dimension of neglect of duties, five questions for the dimension of sleep disturbances, and five questions for items related to the dimension of behavioral disturbances, for example. Already. Now, that's what I think, based on what I've read, which isn't much, there's little theory about it, that's how those items are grouped.
So, in that case I'm going to have to develop the confirmatory factor analysis, that is, I propose the dimensions and then I have to do a pilot test, that is, I have to print the document, go where the people being evaluated are, give them 20 or 30 minutes to complete the instrument, collect the instrument and from that data do statistical analysis.
We're talking about a quantitative phase, mind you, quantitative.
So, I'm going to do statistical analysis to perform my confirmatory factor analysis.
Let's move on to scenario number three.
when the concept is not defined.
When the concept is not defined, there is no theory.
And so here, even in content validity, we had done three tasks, right? If you recall, in the content validity, in scenario one we did one task, in scenario two we did two tasks, in scenario three we did three tasks, meaning that scenario three was the most complicated of all.
Now, speaking of construct validity, I made my approach to the population, I compiled a list of keywords, and with my predefined categories, I conducted an interview focused on the experts. I built my questionnaire, my scale, and presented it to a panel of judges. They graded it for me and I decided to approve it, but I don't have the dimensions.
So, to find the dimensions, I'm going to tell the statistician, you who calculate everything, tell me what the dimensions of my instrument are, and for that I'm going to have to develop the exploratory factor analysis.
So, statistical software, statistics, right? The software, statistics as a tool, will give me those options, those alternatives.
We then have in construct validity, this is like a classic, right?, in the validation of instruments, exploratory and confirmatory factor analysis. Are there other tools to perform this same task? Yes. It's just that we live in a world of dogmas, in a world of closed theories, both at the academic level and at the editorial level of scientific journals, right? In other words, if you perform construct validity using a statistical tool other than exploratory or confirmatory factor analysis, your thesis committee probably won't accept it.
That's the problem.
So, for this reason we always have to learn exploratory and confirmatory factor analysis, but there are more tools to achieve this grouping such as clustering techniques for this third scenario where exploratory factor analysis is performed, because the idea is to reach this point, a factor structure.
This is grouping and in SPC it is called dimensionality reduction because if in principle we have 20 items, theoretically we have 20 dimensions. If we group it into four, then we have gone down from 20 to four.
That's where the reduction in dimensions comes in.
Content validation question, says Ronald Montoya, "Is the 'B' in Ikiken recommended for content validation?"
I think that question is answered by looking at this infographic.
Content validity corresponds to a purely qualitative stage.
It is 100% qualitative.
And in this qualitative stage there are no statistics, no coefficients, no measurements, no mathematical calculations to help us define. There is n't even an algorithm, there's only heuristics. The qualitative phase only goes as far as the uristic tool. The algorithm is now moving into a quantitative phase.
And talking about BDEN means talking about algorithms, that's already quantitative, but deciding whether an item stays or goes is purely the researcher's decision.
So why did he consult the experts?
Their opinions are taken into account, but the author and the person responsible for the instrument is the creator.
Therefore, we can use the BDEN to support us as an assessment rubric. Yes, we can use it as a rubric, but it's not going to help us decide.
In other words, if there are five judges, three in favor and two against, it's not that the IEM should stay by majority vote, right?
For that reason, they do not need to be odd.
Ultimately, the decision is made by the researcher himself, since it is a purely qualitative stage.
Okay, so there's your answer.
Once we have the factor structure of our instrument, let's move on to reliability, or dependability, as some call it.
Reliability or dependability.
These are two concepts. Uh, they're synonyms, right? They are not synonyms.
But for measurement purposes they are equivalent.
There are concepts that come from different fields of knowledge that have procedural but not conceptual equivalence. It's the example, because it's the case, for example, of dimension and magnitude, right? Logical dimensions, physical magnitudes. They are not synonyms, but for measurement purposes they fulfill the same role.
They have the same procedural function.
The same thing happens with reliability and dependability, which is why many people think they are synonymous for measurement purposes, and are only equivalent for procedural purposes. Already. Reliability is a term that comes from the human sciences, that is, from this paradigmatic world of qualitative research, right?
That some people are still philosophizing.
Philosophy is the starting point of science, not its tool; it is the starting point. The reason why we do science is purely philosophical.
Then, the part of philosophy that crosses the field of science is epistemology.
Well, it turns out that in the exact sciences, right?, this is the quantitative paradigm, some would say. This concept is that reliability and measurement effects are equivalent. But the correct term would be reliability. And I'll explain why. Because reliability is evaluated at what level. Let's remember, reliability is evaluated quantitatively.
Reliability has two components: internal consistency and stability, which is what we are going to look at right now. But reliability is a concept that corresponds to a quantitative phase.
So, if we had to choose just one word between reliability and dependability, which one would we choose?
Easy. If mathematics is needed to evaluate this property, it is an exact science, not a human science. Therefore, the winning term here is reliability. It's the winning term, but if someone calls it reliability for measurement purposes, that's understandable. It turns out that, and here we're already changing things, aren't we? We are changing.
Okay, we'll leave it as reliable here and here too.
It turns out that this property has two large dimensions, right?
Properties also have dimensions; they have two major dimensions.
Internal consistency, let's call it that in general terms, represented by its Chrombatch alpha and not just its Chrombatch alpha. and external consistency, better known as stability. So, reliability has two aspects, internal consistency and external consistency, but external consistency is better known as stability. Some authors call it external consistency. Note, yes, there are authors who call it external consistency. Already.
On the other hand, to the Alfa de Chroms, to the terrain of the Alfa de Chrombach, where Alfa de Chrombach is a gamonal, no one disputes that it belongs to the terrain of internal consistency. Everyone agrees on that.
But some authors call stability external consistency, and that's correct because it is an extrinsic property of the instrument; it has nothing to do with the instrument itself.
Internal consistency and stability together form the concept of reliability. That is why the concept of reliability does not appear in the instrument validation pyramid; internal consistency and stability do appear, because together they make up reliability. And why have I separated them when everyone else puts them together? It is almost standard that everyone links them to internal consistency and stability. They lump them all together, to the point that they say, "The validity of an instrument consists of content validity, construct validity, and reliability," and that's where they stop, right? They don't reach criterion validity and they don't reach performance validity. Because, as in any other line of research, criterion validity and performance validity require training in advanced statistical analysis—let's call it that, let's give it that name, advanced statistical analysis.
So, there are some who are allergic to statistics and retreat into the qualitative phase of the research. There, in their den, they hide under the bed because they don't want to take a statistics workshop and they tell themselves they are qualitative researchers, right? Ignoring everything that can be done in a line of research.
So, if these self-proclaimed qualitative researchers already find it difficult to reach construct validity or reliability in general terms, they're going to be even more afraid of criterion validity and performance validity, right? What's the treatment for their madness? That they take a statistics course. Simple. That's the treatment for their madness.
So why did I separate reliability into stability and internal consistency? For that very reason.
Because when you put these two together, everyone forgets about stability, as if it did n't exist. As if it didn't exist.
And then they summarize by saying that an instrument is valid when it has content validity, construct validity, and reliability, and that's where they stop. And on top of that, when they talk about reliability, they don't even talk about internal consistency and stability; they forget about stability and think that only internal consistency is reliability. That's why we've separated them, and also because there's a more important methodological criterion here, a technical criterion. Internal consistency is an intrinsic property of the instrument, directed inward. That is, when internal consistency fails, it's the instrument's fault; it's poorly made.
Stability is an extrinsic property of the instrument, directed outward; that is, it's not at fault. The poor instrument is n't to blame for you having applied it incorrectly, right? Because, for example, standardization is required, a manual for applying the instrument is needed, and training is required. of the evaluators. So, if there's no manual, you yourself won't be able to achieve stability; you haven't written the manual, and if those who are going to use the instrument aren't trained, they wo n't have this skill.
So, the problem is with the instrument, right? The problem isn't with the instrument; the problem is with the instructions that should accompany the instrument, and the people who are going to use the instrument haven't read the instructions. Ah, that's an external property, an external problem, an extrinsic property. So, being like that, internal consistency, an intrinsic property, and stability, an extrinsic property, must be handled separately; they are completely different things.
And yet, in theory, and so far, everyone continues to treat them as one and the same, right? Reliability as internal consistency and external consistency. Let's talk then about internal consistency. Let's only talk about internal consistency. That's where Cronbach's famous alpha resides, where it reigns supreme, where it is the most powerful, the all-powerful.
Internal consistency is a measure of variability The contribution of each item to the final result.
And the variability reflects the discriminating capacity of an instrument. That is, when you give students an exam, it's to see who studied and who didn't. And that will be reflected in the number of passes and failures. It's not that we want to fail the students, no. What happens is that we want to pass those who have studied, and for those who have n't, well, too bad.
Once a teacher said to me, "How can you think that an exam should have passes and fails when the teacher should expect everyone to pass?" Of course, of course, of course. As a doctor, I also think the same way, that when I do glucose tests on patients, they all come back normal. Of course, it's also desirable, I wish that every time they measure their fasting glucose, and even people close to them, family, friends, have their glucose tests done, I hope it comes back normal, but sometimes it doesn't.
And that's precisely why we do the test, because some people have elevated glucose levels, and if they have elevated levels, we don't want to worry that... have diabetes. And what we don't want is for them to have diabetes, that's why we screen them, that's why we take the measurement. And so, measuring glucose means identifying those who have elevated glucose levels compared to those who don't. That's called the discriminatory capacity of a test.
These properties don't only apply to questionnaires and scales, they apply to any measurement system. So, the instrument validation course shouldn't be called that, but rather measurement systems. It turns out, then, that internal consistency evaluates discriminatory capacity. I'm not talking about overall reliability, but only internal consistency.
And we calculate it with Chrombatch's alpha. It's a mathematical relationship, right? There are even two methods, but the one most people use is the item variance method, where alpha is equal to the number of items divided by the number of items minus 1, and this multiplied by the absolute value of 1 minus the sum of the item variances divided by the total variance.
Why?
I need to clarify. This is because some people are handing everything over to artificial intelligence. There's a problem with artificial intelligence. Anything you don't specify, it randomizes. Let me explain. If you tell artificial intelligence, "Draw me a person eating an apple," sometimes it will draw a woman, sometimes it will draw a man. If you want a man eating an apple, just tell it that: " Draw me a man eating an apple." Then, sometimes it will draw an older person, sometimes a child. If you want an older person, an older man eating an apple, just tell it that: "Draw me an older man eating an apple."
Then, sometimes it will draw him with glasses and sometimes without. If you wanted him with glasses, draw me an older man with glasses eating an apple. And so the instructions get longer and longer, so long it goes on to infinity. And anything you do n't tell it... Randomize it.
This seems logical and very simple, very simplistic.
What's the problem? You hand your Excel spreadsheet to the AI and tell it, "Calculate the Alpha of Chrombatch." And it turns out the result won't be the one your professor or your jury calculates. Your jury will also calculate it, and it won't be the same.
Then you say, "How strange, isn't it?"
José told me that AI, as a mathematician, is excellent, and yes, it is true, AI does not make mistakes when performing mathematical calculations. He's not hallucinating there.
So how is it possible that your Chrombat alpha calculated with GPT chat is different from your teacher's calculated with SPCS? No? Where is the situation? It turns out there are two ways to calculate the alpha of Chrombatch, and you didn't know that. And when you asked the GPT chat to calculate your Chrombatch alpha, it randomized and used a different method than the one used by SPCS. That's why they don't match, but since you didn't know that, you didn't realize it and that's where you made a mistake, you fell for it completely, as we said, right?
Then you have to tell the AI, you hand it your Excel file and say, "Calculate Chromeb's Alpha using the item variance method." And when you do your report, your final thesis report, your scientific article, you put there Colomb's alpha calculated by the method of item variance.
That's just one example. This can happen with any other statistical procedure. Ah, like the fact that the software assumes your data has a normal distribution when it doesn't, or vice versa.
The AI already performed the normality test, but it didn't warn you. He did n't warn you. And that's where you fell for it again, didn't you? When it does n't fail in mathematics and statistics, it does n't fail. That's why they are exact sciences, because mathematics is an exact science. Well, statistics are probabilistic, some say. They are still numbers, and any calculation you do should match between one software and another. That's how AI does it.
Well, it turns out that this alpha of Chromb is a relationship, if we look at the algorithm, it is a relationship between the variability of the items and the total variability, that is, how much the variability of an item contributes to the total variability, which is what we know as the discriminant index, discriminant capacity, or internal consistency. So, let's look at an example. If I have a Chromebatch alpha calculated from five items, which gives me 079, I already have five items. The instrument can have the necessary number of items, right? There is no strict rule. Let's assume it has five items. I calculate the alpha of Chrombatch and then evaluate the variability of each item. Therefore, there are items with small variations. The smallest here would be 040, the highest would be 050.
And if I remove the item with the lowest variability, the alpha of Chrombatch increases.
But if I remove the item with the greatest variability, the alpha of Chrombatch decreases.
So some people use this trick, right? They want to increase their Chrombatch alpha, they calculate the variability of each item, which can be with the variance, the standard deviation, with the dispersion measure of their preference, they eliminate the item that has the least variability to increase their Chrombatch alpha, but what they are doing is breaking the content validity. No, do n't do that. They are breaking the validity of the content. What can be done in that case is to rewrite the item, rewrite the item, change the way the item is written so that it expresses greater variability, right?
[snort] This is a method for evaluating reliability, isn't it? Chrombatch's alpha removing the item. There are now several statistical tools for this, depending on the nature of the items, right? In the past, test-retest was widely used, and I prefer Chrombatch's alpha because it expresses greater discriminatory capacity than a Tretest.
In statistics, you have to use the tool that has the highest probability of expressing the property you are looking for.
And then there's... uh, where is it? It slipped through here, didn't it? This is reliability. And then there's McDonald's Omega, right?
It has become very fashionable because it is not affected by the number of items. It turns out that Chrombatch's alpha is sensitive to the number of items, like many statistical procedures, right? The famous Chicano is also sensitive.
to the lowest number of expected squares, and that is why corrections exist. In other words, statistics are not perfect, they are not all-powerful, you have to know how to interpret them.
And in the case of Chrombatch's Alpha, which has shown to be sensitive to the number of items, they have developed this new coefficient, McDonald's Omega, which they can also calculate by AI.
In other words, it's easier to ask artificial intelligence to calculate this for me, but we also need to know how to interpret it, right? Well, time is passing us by and we have even more properties. We moved on to the property of stability.
When we talk about stability, there is a concept of repeatability, which is when the same evaluator using the same instrument obtains the same result. We are talking about intra-rater stability.
Sometimes this is misleading because we create a measurement system and since we apply it time and time again it seems stable because even though we haven't written a guide for implementing the instrument, we have it mentally because we developed it ourselves, but when we ask someone else to use this measurement system, they won't follow the same steps as us.
And that's where the concept of reproducibility comes in.
When different evaluators using the same instrument with the same person being evaluated obtain the same result, it is called reproducibility.
Now, if there is no reproducibility in an instrument, the problem lies with the evaluators. They are not matching, they are not agreeing for reproducibility. Therefore, the lack of reproducibility is solved by training the evaluators. What happens if there is no repeatability? In other words, not even the evaluator himself, the creator of the instrument in many cases, can achieve the same results because he is not following a systematic sequence of steps to arrive at the measurement value. How is repeatability solved? Writing a manual.
writing a manual. So, when it comes to measurements, we need to write the manual because the measurements have to be repeatable.
And that's a principle of science, is n't it? Verifiability.
So, there are two properties that need to be evaluated here, repeatability and reproducibility, but as we can see, these are also two external properties, two extrinsic properties, unlike internal consistency, unlike the Chrombatch alpha, which is related, right? If Chrombatch's alpha itself is affected by the number of items, it's clear that it's an intrinsic property, isn't it? which belongs to him, even depends on the number of items. If poor alpha of Chrombatch. Poor alpha Chrombatch.
Okay, let's go over the last properties.
Criterion validity.
There are several ways to talk about performing criterion validity. When we have an external reference and it is evaluated at the same time, we speak of concurrent validity.
But this external reference cannot always be evaluated at the same time.
So we have to evaluate it as it evolves, right? In health, it's about evolution. In every field of knowledge there will be a way of seeing the outcome.
When it is with the outcome, it is called predictive validity and some authors have even described retrospective validity, but the most common of all criterion validity is concurrent validity.
Some authors call it external criterion validity. Well, that's understood, isn't it? If stability was already an extrinsic property, then criterion validity was even more so, wasn't it? Because it's higher up in the pyramid. So, this has to do with a measurement of a standard, a measurement of a pattern with which we can compare our own measurements. Its form of evaluation will depend on the nature of the variables.
A simple Pearson or Spearman correlation is evident, depending on the behavior of the data; it will be sufficient when the final measurement value is numbers, which could be the case of a scale, or a Coen layer when the final measurement value is dichotomous, as is the case of a questionnaire.
Here we have then the case of an instrument with a dichotomous result.
Instrument one is the evaluation instrument that we are creating, which can be a questionnaire, that's why its result is dichotomous, right? That's why we gave the presentation.
Instrument two is the standard instrument, the Gold Standard. We apply a Cohen layer and here the interpretation becomes the degree of validity.
Critical interpretation, the purpose of the study, is different from statistical interpretation.
The answer to the purpose of the study is different from the statistical interpretation.
If I get a Cohen's layer of 0.9, I say, well, that's an acceptable Cohen's layer.
But if I am in the context of instrument validation and I am evaluating criterion validity, then I will say that my instrument has acceptable criterion validity, right? They are two different things. The technical reading of the statistical result is a purely statistical interpretation and the interpretation or answer to the purpose of the study, which is to say that my instrument is stable. So, if I find myself at the level of criterion validity, the statistical result has a technical interpretation, there is agreement, but for the purpose I am using for my instrument, there is criterion validity. So, they are two different things.
Technical statistical interpretation, interpretation as a response to the purpose of the study. That's why we said that each of these, each of these levels, has different purposes.
And if I'm using and if my final measurement value is a numerical variable, well, the Pier correlation applies here too, right? Well, from a technical statistical point of view, I mean, yes, it has an acceptable correlation.
If the final measurement value is a number, as would be the case with a scale, but if I am in the context of instrument validation, I would say whether my measurement, my instrument has acceptable criterion validity.
Well, finally we have the diagnostic performance which involves the construction of the identification of the condition of each of the evaluated individuals with respect to an external criterion. We continue with the external criterion and the results of my test, which we can call a positive or negative test, to calculate sensitivity, specificity, and positive and negative predictive values.
Therefore, we construct a diagnostic performance curve and choose the cutoff point by probability in some cases, and in other cases we intentionally move it to detect the largest number of cases in the population, increasing sensitivity levels and sacrificing specificity levels. There are tests, diagnostics, or any measurement system, such as the ELISA test for diagnosing BH infection, which is not highly sensitive but rather unspecific. In other words, you might get a positive result, but don't panic too much because there are cross-reactions.
And then those who test positive take a Western Blood test, which is highly specific, but not very sensitive. Now, if the western block test comes back positive, then the infection is definitely present.
Then this cut-off point can be probabilistic for detection with better levels of sensitivity and specificity, or from the level of sensitivity required we modify the cut-off point, but based on the diagnostic performance curve, the rock curve. And with that, we've done a super-fast review of instrument validation. What does he have to do with all this?
Validation by judges, therefore, has to do with the validity of the content. What does the Chrombatch alpha have to do with all this? Well, it has to do with internal consistency, which is part of reliability, equivalent to reliability in the social sciences, right? All these procedures can obviously be accelerated with artificial intelligence tools, but you have to know how to use them.
So, today's podcast consists of reviewing these concepts so we can then hand our Excel spreadsheet to artificial intelligence and say, "I want you to calculate Chrombatch's alpha using the item variance strategy and give me an interpretation to support my work. Thank you very much for your attention."
Related Videos

Escaping the Fog
LogicLemurGaming
760 views•2026-06-03

Olympiad Mathematics | Indian | Can You Solve This One?
PhilCoolMath
650 views•2026-06-03

A Brutal Radical Expression Made Easy! The Shortcut Changes Everything.
tamoshop
112 views•2026-06-02

V : jee main /advance class 11 mathematics : Binomial Theorem class-1 ( 29 may 2026 )
dcamclassesiitjeemainsadva9953
125 views•2026-05-29

Is This Pentomino Tileable?
3cycle
241 views•2026-05-30

This Sudoku Has Many Lines!!
CrackingTheCryptic
2K views•2026-05-29

Olympiad Mathematics | Indian Can You Solve This One?
PhilCoolMath
268 views•2026-06-02
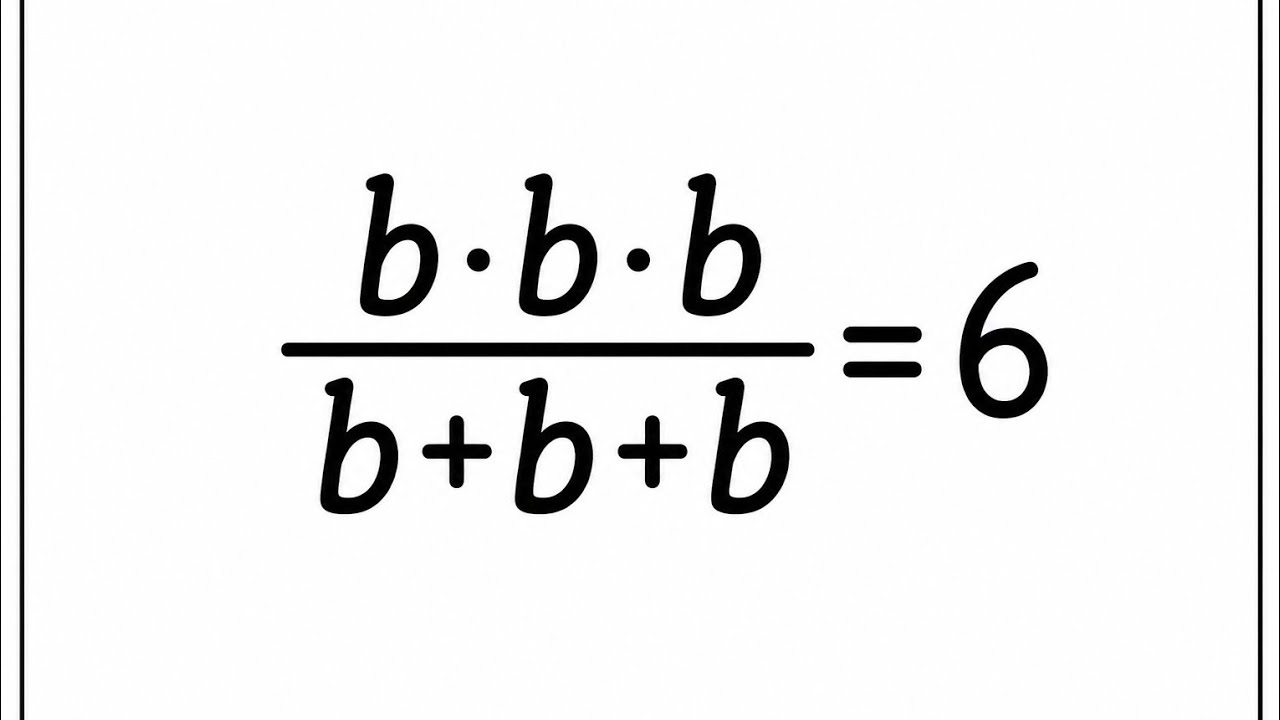
Olympiad Mathematics | Indian | Can You Solve This?
PhilCoolMath
669 views•2026-06-02



