This video teaches how to perform hypothesis testing to compare two population proportions (P1 and P2) from independent samples. The process involves: (1) stating null hypothesis (P1 = P2) and alternative hypothesis (P1 > P2, P1 < P2, or P1 ≠ P2), (2) checking assumptions including random sampling, independence, and success-failure conditions (n1P1-hat(1-P1-hat) ≥ 10 and n2P2-hat(1-P2-hat) ≥ 10), (3) calculating the pooled proportion P̂ = (x1 + x2)/(n1 + n2), (4) computing the test statistic Z = (P1-hat - P2-hat) / √[P̂(1-P̂)(1/n1 + 1/n2)], and (5) comparing the p-value to the significance level α to make a decision. The video demonstrates this with an example comparing internet access rates between urban (n1=800, x1=338) and rural (n2=750, x2=264) households, finding sufficient evidence at α=0.05 to support the claim that urban households have higher internet access rates.
Inferences on Two Samples (Part 1)Added:
hi guys welcome back so in this chapter we are doing inferences on two samples in the previous two chapters we learned inferences regarding a single population parameter such as P population proportion right mu a population mean Sigma population standard deviation and Sigma squared population variance right now we're going to modify the inferential methods we learned in those chapters slightly so that we can compare two population parameters instead of one so in the first section we're going to be doing an inferential methods for comparing two population proportions P 1 and P 2 okay and in the next section we're going to focus on two population means mu1 and mu2 okay now the inferential methods that we're going to learn depend on whether the data are from an independent or dependent sample so let's learn first about independent and dependent samples all right okay so let's compare the following studies scenario one among holistic eczema remedies does one perform better than the other to answer this question researchers applied remedy a to one part of the subjects arm and remedy B to a different part of the subjects arm to determine the proportion of subjects whose eczema healed now the same situation in scenario two but how the individuals are selected for each group is different from a scenario one so pay attention to that part okay all right scenario two among a holistic eczema remedies does one perform better than the other to answer this question researchers randomly select eczema sufferers and divide sample into two groups one group receives remedy a and the other group receives remedy be alright all the study is the same what's the different about them okay so for scenario one right so we have individuals who have eczema so let's say we have individuals who have eczema right and in remedy a was applied to one arm so here here and there so this is remedy a when we a remedy a right and remedy B was applied to their other arm so it's gonna be like this okay so that's scenario one right so co2 is a little bit different you had this group of people and eczema suffers right and then they are randomly broken up to two groups so so let's say this is good one and this is a group too and everyone in the first group received remedy a so they all received remedy a right and everyone in the other group received remedy B so this will be remedy B so in our first example so in Scenario one right once you decide where you're going to put the remedy a remedy B is already chosen you are just gonna go to their other arm so once an individual is selected one of his or her arm is matched up with their other arm verses in scenario to these individuals in the first sample is one okay they have nothing at all to do with the individuals in the second sample they randomly chosen to be in remedy a and these one right here are randomly chosen to be in remedy B group right so these two groups have nothing to do with each other okay so in Scenario to the sampling method is independent since the individuals selected for one sample do not dictate which individuals are to be in a second sample and in scenario one the sampling method is dependent because the individuals selected to be one sample are used to determine the individuals to be in the second sample and we usually call dependent samples matched pair samples so you know example one person's right arm can be matched up with the same person's left arm right okay so of the above scenarios state whether it's in Japan then independent Oh we just did that I'm walking let's write the answer then okay scenario one okay would be dependent sampling or matched pairs alright yes scenario two independent sampling okay so let's take a look at an example determine whether the sampling method is independent or dependent number one a researcher wants to know whether the state quarters introduced in 1999 have a mean weight that is different from traditional quarters he randomly selects 18 state quarters and 16 traditional quarters and compares their weights okay so well this sampling method is independent because the sample from state quarters are not related to the sample from a traditional quarters right the quarters in the first sample are not used to determine the quarters in the other sample so the sampling method is independent okay number two a sociologist wishes to compare the annual salaries of married couples in which both spouses work and determines each spouse annual salary okay so this sampling method is a dependent matched pairs because once a wife is selected right her husband is automatically enrolled in the study so the wife and husband team is matched up okay so this will be dependent okay sampling method or matched pairs right I'm going to write a note here okay that the wife and husband team is matched up okay okay so now we are ready to do some inferences on two population parameters alright so first we're gonna look at inferential methods for comparing two population proportions p1 and p2 okay so hypothesis testing regarding two proportions from independent samples so we're gonna focus on independent samples okay so here's an example now while we're doing this example right you're gonna see a new sampling distribution and the sampling distribution of two proportions okay and also a new test statistic formula but just like I did in the last chapter of hypothesis testing at the end of this example I'm going to give you a summary of steps so you can use them as a guide okay okay so let's read the example an economist believes that the percentage of urban households with internet access is greater than the percentage of rural households with internet access he obtains a random sample of 800 urban households and finds that 338 of them have internet access he obtains a random sample of 750 rural households and finds that 264 of them have internet access tests The Economist's claim at the alpha equals 0.05 level of significance okay so we're testing a claim at alpha equals 0.05 level significance right here right so this is how we know that we're doing a hypothesis testing okay if this was a confidence inable problem then you will be given a confidence level that's how you know this is a this testing problem right now also since we're talking about percentage percentage is a proportion okay so percentage right here okay proportion that's P my hold is from p1 and this is p2 okay why because we have two populations we have urban households population 1 and we have rural households that will be population 2 right okay so here's the approach so we're trying to determine whether the percentage of urban households with internet access is greater than the percentage of rural households with internet access and here are our data let's summarize this okay so for the sample of 800 urban households so let's call that a new one right because we have two sample sizes so N 1 that would be 800 households so I'm gonna put urban households okay that's gonna be our population 1 and from the population you select 800 households that's gonna be n1 okay and then x1 is going to be the number of successes so that will be 338 households that have internet access right so that's for the first group and we have a second group which is rural households okay and the sample size let's call that a new - there will be 750 households and of them let's see here 264 of them have Internet access so we're gonna call that X chill okay so let's figure out the sample proportion right so you remember sample proportion that's x over N but for this one it's going to be x1 over anyone okay so we call that p1 hat okay that's the sample proportion for the first sample okay that would be 338 over 800 so that's gonna be point four two two five so forty two point 25 percent of the sample of urban households have internet access and how about p2 hat that'll be 264 two over 750 okay so that's point three five two so that's thirty five point two percent of the sample of rural households have internet access okay so what was the economists claim again it was the percentage of urban households with internet access is greater than the percentage of rural household with Internet access right so can we just say that forty two point twenty five percent is larger than thirty five point two percent so we were supporting his claim well not really I mean not yet right we're not sure yet right we cannot just conclude that the percentage for urban households is larger than percentage of rural households because these are just samples of 800 people on 700 people right maybe we got a higher percentage for the sample of urban households randomly by pure luck and if you find a different sample you might get a percentage that is not as high as forty two point twenty five percent who knows or maybe we get a different sample for rural households we get a higher right maybe you just happened to get a sample like that so what we need analyze here is that how different these proportions are these forty two point twenty five percent and thirty five point two percent how different so is the difference statistically significant right so we want to know how different these proportions are based on our sample sizes and the amount of variations we expect so if the difference is large okay if there's a huge difference between these two values then we're gonna say okay it's hard to believe that this big difference happened randomly by chance you know so the difference is way too big to happen by random it is unusual to see a big difference like this so we're inclined to say that okay we have enough evidence to suggest that the true percentage of urban households with internet access is greater than the percentage of all rural households with internet access and if the difference is not so big then we say all right the percentage of urban households with internet access is pretty much the same as the percentage of rural households with internet access so there's no difference oh so you guys remember the definition of the null hypothesis it's a statement of no difference right so that will be our null hypothesis for this one okay no difference between the percentage of earnest holes with Internet access and the percentage of rural households with internet access all right so let's do step 1 state the null and alternative hypotheses okay you know what let me write here so 8 0 81 okay we're going to use p1 okay I'm going to write note here we're going to let p1 represents the percentage of urban households with internet access and we're going to let P to represent the percentage of rural households with internet access okay so this is the population proportion of urban households with internet access in rural households with internet access okay so that's going to be p1 and p2 so a 2-0 assumes that p1 and p2 are equal meaning there is no difference between these two proportions okay now the economists claim is that p1 is greater than p2 so this is what we want to find evidence for so p1 is greater than p2 now in order to do inferences about two population proportions from independent samples first we need to determine the sampling distribution of the difference of two proportions so then I take a look at that in the next page ok so remember that the sampling distribution of P hat is approximately normal I'm going to write a note here okay it's approximately normal with mu sub P hat equals P and Sigma sub P hat equals the square root of P times 1 minus P over N if number 1 simple random sampling is used in number 2 sample observations are independent so n is less than or equal to 5% of the entire population and also n times P times 1 minus P is greater than or equal to 10 right so if these three requirements are satisfied then we can say that the sampling distribution of P hat is approximately normal with these two mean standard deviation okay so this is from the sampling distribution chapter now we're going to use this information to get the sampling distribution of the difference between two proportions so it's going to be P 1 hat minus P 2 hat okay so the distribution is approximately normal if these three requirements are satisfied number 1 samples are obtained independently using SRS number 2 sample observations are independent okay and number 3 + 1 times P 1 hat times 1 minus P 1 hat is greater than or equal to 10 and also you're gonna check n 2 times P 2 hat times 1 minus P 2 hat is it greater than or equal to 10 and again if these three requirements are satisfied then we can say that the sampling distribution of P 1 hat minus P 2 hat the difference between two proportions is approximately normal with mu sub P 1/2 minus P 2 hat equals P 1 minus P 2 that's the mean and the Sigma sub P 1/2 - key to hat will be the square root of P 1 times 1 minus P 1 and over N 1 plus P 2 times 1 minus P 2 over n + 2 so this is the mean and this is a standard deviation of the sampling distribution of the difference of two proportions now the standardized version of p 1 hat minus p 2 hat is then written as Z equals P 1 hat minus P 2 hat that's going to be our point estimate P 1 minus P 2 divided by you're basically subtracting the mean from the point estimate ok divided by the standard deviation so the square root of P 1 times 1 minus P 1 over N 1 plus P 2 times 1 minus P 2 over n 2 so this part is our point estimate and this is going to be the mean and this is the standard deviation so this is our test statistic Z naught ok so it's going to be P 1 hat minus P 2 hat now I want you to recall that when we're doing hypothesis testing we always assume that the null hypothesis is true so our null hypothesis is P 1 equals p chip right so if we assume that this is true then P 1 minus P 2 equals 0 ok because if you have P 1 minus P 2 right if you subtract P 2 from both sides that's gonna give you p1 minus p2 equals zero okay so this part right here is actually zero okay so the numerator becomes just p1 hat minus p2 hat and also since we assumed that p1 equals p2 we're gonna call that value P which is the common population proportion right but since P is unknown we're gonna use something called the pooled estimate of P and we use this notation P hat and that is x1 plus x2 divided by n1 plus n2 so you're kind of inviting everybody to the party here so we take the total of the number of successes x1 and x2 and then divide that by the total of both samples okay so it's gonna be P hat times 1 minus P hat over and 1 plus P hat times 1 minus P hat over n2 and if you factor out the numerator here then you will get P 1 hat minus P 2 hat divided by the square root of P hat times 1 minus P hat times the square root of 1 over N 1 plus 1 over N 2 ok so this is our test statistic okay so let's start working on our test statistic okay so let's organize the information we have so X 1 that was 338 households and this is for urban households and then we have a rule household right okay so three and thirty eight number of successes that will be number of households that have internet access okay and then and one that's gonna be eight hundred okay and then p1-hat is three and three eight over eight hundred which is 0.42 to five okay and x2 that was 264 and n to 750 households and P to hat that will be 264 over 750 which is 0.35 - okay all right so now we can go ahead and check the assumptions okay we're gonna check the requirements here I'm gonna put urban here and here I guess I'm gonna do requirement check for both groups right okay number one SRS this is a random sample of 800 households and also random sample of 750 households so that will be okay for both all right groups and then number two sample observations are independent okay so is anyone less than equal to five percent of the entire population of urban households sure 800 households is less than or equal to five percent of the entire population of urban households yeah I will say so same team for the rule all right so 750 is that less than or equal to five percent of the entire population of rural households yes absolutely okay number three and 1 times P 1 hat so anyone is 800 times P 1/2 point for 2 to 5 times 1 minus Oh point four two two five is this greater than or equal to ten okay well when you punch these numbers in your calculator you should get about 195 so it is greater than ten and for rural households it's gonna be 750 times point three five two times one minus point three five two so that's gonna give you about one hundred seventy-one so that's again greater than ten so that checks okay so by the way I want to see you do this calculation on the exam okay don't just write out the formulas all right so all the requirements are satisfied so we are good to proceed to step 3 okay select a level of significance alpha okay so the problem says alpha equals 0.05 so let's use that okay step 4 compute the test statistic okay so let's write down the formula first so Z naught equals P 1 hat minus P 2 hat divided by the square root of P hat times 1 minus P hat times the square root of 1 over N 1 plus 1 over N 2 ok so remember here that the P hat is the pooled estimate right so it's gonna be x1 plus x2 divided by n1 plus n2 ok so let's calculate that first so P hat equals so X 1 BB 338 plus 264 divided by 800 plus 750 okay so that's gonna be 602 over 1550 ok now this is nothing gonna be a terminating decimal like these two so I'm just gonna keep it as a fraction because I want to get the exact answer okay so let's see so p1-hat that's gonna be 0.42 to 5 minus P 2 hat 0.35 2 and divide that by the square root of P hat which is just 1 600 to over 15 50 times 1 minus 600 to over 15 15 ok times the square root of 1 over 800 plus 1 over 750 ok so you're gonna punch these numbers in your calculator but be careful here you're gonna put a parentheses around the numerator that's 1 and then you're gonna put another parentheses around the denominator like this ok make sure you do that otherwise you're not gonna get the correct answer all right so if you do you're gonna get two point eight four six okay so let's use our calculator test function to prop Z test to find our test statistic okay okay so you go to stat and you go to tests and you choose number six to prop Z test okay two population proportions Z test okay go ahead and press enter on that alright so x1 that is gonna be 338 okay that's the number of successes for the first group right anyone that will be 800 and X to 264 and - 750 okay and then our alternative hypothesis is p1 is greater than p2 so we choose the last one and go ahead and press calculate okay here we go Z equals two point eight four six so that's the test statistic we calculated using the formula the same thing right okay now this will also give you the p-value which is point zero zero two two so let's keep that in our mind right because we're gonna be using that in the next step okay perfect all right now I'll down here they give you a p1 hat and then p2 hat and also P hat okay and the end of one and two all right okay so here is the summary of the steps that we just used for the test function to prop Z test okay okay so let's write down our test statistic it was z equals two point eight four six right okay so now the question is is our test statistic of two point eight four six in the critical region right meaning is it unusual is this statistically significant how do we determine that well we can use either the classical approach or the p-value approach okay so let's look at the classical approach first so I'm gonna sketch the distribution okay our alpha is 0.05 so since it's a right tailed test we have our critical value on the right side of the distribution so Z sub point oh five that's in Norma point 9501 so that's gonna be 1.645 okay so our critical region is on the right side so this is a critical value I'm gonna perceive e here okay all right so our test statistic is two point eight four six so that's definitely on the right side of the critical value so that's our I'm gonna go like this this is Z naught which is two point eight four six okay all right so step six well we know that our test statistic two point eight four six is greater than our critical value of one point six four five in the right tailed test right so since the test statistic is in the critical region okay we reject the null hypothesis okay okay so let's look at the p-value approach okay so test statistic is two point eight four six and the p-value is the area to the right of that test statistic okay and we already got that from the calculator function to prop Z test so let's write that down so we got p-value equals point zero zero two 0.02 - okay all right so step six you're gonna compare the p-value with alpha and our alpha is 0.05 so definitely the p-value is less than alpha so we reject the null hypothesis okay step 7 the final conclusion so there is sufficient evidence that alpha equals 0.05 level of significance to conclude that that percentage of urban households with internet access is greater than the percentage of households with internet access okay okay so that's it for this video in the next video we're gonna start by going over the summary of the steps for testing hypotheses about the difference of two proportions then we gonna look at one more example okay see you in the next video bye guys
Related Videos

Olympiad Mathematics | Indian | Can You Solve This One?
PhilCoolMath
650 views•2026-06-03

Escaping the Fog
LogicLemurGaming
760 views•2026-06-03

A Brutal Radical Expression Made Easy! The Shortcut Changes Everything.
tamoshop
112 views•2026-06-02

V : jee main /advance class 11 mathematics : Binomial Theorem class-1 ( 29 may 2026 )
dcamclassesiitjeemainsadva9953
125 views•2026-05-29

Is This Pentomino Tileable?
3cycle
241 views•2026-05-30

This Sudoku Has Many Lines!!
CrackingTheCryptic
2K views•2026-05-29

Olympiad Mathematics | Indian Can You Solve This One?
PhilCoolMath
268 views•2026-06-02
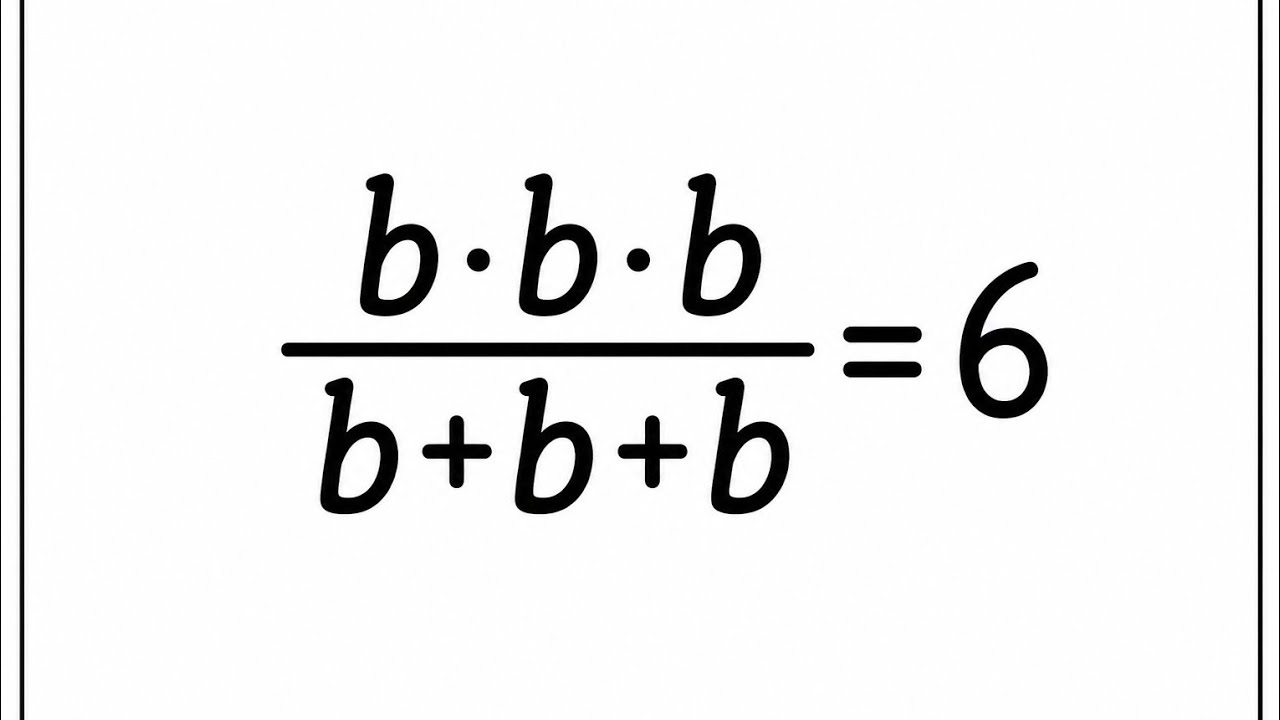
Olympiad Mathematics | Indian | Can You Solve This?
PhilCoolMath
669 views•2026-06-02



